
Distributed Database Systems
A
distributed database is basically a database that is not limited to one system;
it is spread over multiple computers or over a network of computers.
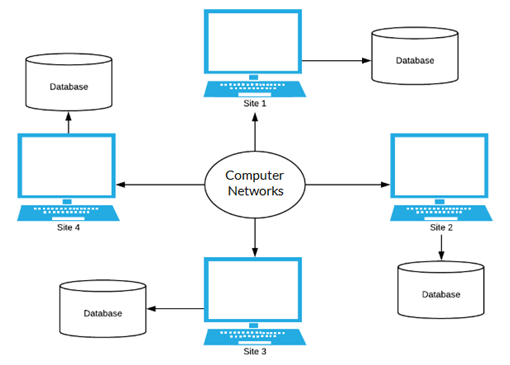
A
distributed database system is located on various sites that don’t share
physical components. It may be required when a database has to be accessed by
various users globally.
Distributed Database System Types:
1. Homogeneous Database: In a homogeneous
database, all different sites store database identically. The operating system,
database management system and the data structures used – all are same at all
sites. Hence, they’re easy to manage.
2. Heterogeneous Database: In a heterogeneous
distributed database, different sites can use different schema and software
that can lead to problems in query processing and transactions. Also, a
particular site might be completely unaware of the other sites. Different
computers may use a different operating system, different database application.
They may even use different data models for the database. Hence, translations
are required for different sites to communicate.
Distributed Data Storage
There are 2 ways in which data can be stored on different
sites. These are:
1. Replication
In this approach, the entire relation is stored redundantly at 2 or more sites. If the entire database is available at all sites, it is a fully redundant database. Hence, in replication, systems maintain copies of data.
This is advantageous as it increases the availability of data at different sites. Also, now query requests can be processed in parallel.
However, it has certain disadvantages as well. Data needs to be constantly updated. Any change made at one site needs to be recorded at every site that relation is stored or else it may lead to inconsistency. This is a lot of overhead. Also, concurrency control becomes way more complex as concurrent access now needs to be checked over a number of sites.
In this approach, the entire relation is stored redundantly at 2 or more sites. If the entire database is available at all sites, it is a fully redundant database. Hence, in replication, systems maintain copies of data.
This is advantageous as it increases the availability of data at different sites. Also, now query requests can be processed in parallel.
However, it has certain disadvantages as well. Data needs to be constantly updated. Any change made at one site needs to be recorded at every site that relation is stored or else it may lead to inconsistency. This is a lot of overhead. Also, concurrency control becomes way more complex as concurrent access now needs to be checked over a number of sites.
2. Fragmentation
In this approach, the relations are fragmented (divided into smaller parts) and each of the fragments is stored in different sites where they’re required. It must be made sure that the fragments are such that they can be used to reconstruct the original relation (no loss of data).
Fragmentation is advantageous as it doesn’t create copies of data, consistency is not a problem.
Fragmentation of relations can be done in two ways:
In this approach, the relations are fragmented (divided into smaller parts) and each of the fragments is stored in different sites where they’re required. It must be made sure that the fragments are such that they can be used to reconstruct the original relation (no loss of data).
Fragmentation is advantageous as it doesn’t create copies of data, consistency is not a problem.
Fragmentation of relations can be done in two ways:
- Horizontal
fragmentation – Splitting by rows – The relation is fragmented into groups
of tuples so that each tuple is assigned to at least one fragment.
- Vertical
fragmentation – Splitting by columns – The schema of the relation is
divided into smaller schemas. Each fragment must contain a common
candidate key so as to ensure lossless join.
In certain cases, an approach that is hybrid of
fragmentation and replication is used.
Functions of Distributed database system:
- Keeping
track of data –
The basic function of DDBMS is to keep track of the data distribution, fragmentation and replication by expanding the DDBMS catalog. - Distributed
Query Processing –
The basic function of DDBMS is basically its ability to access remote sites and to transmit queries and data among the various sites via a communication network. - Replicated
Data Management –
The basic function of DDBMS is basically to decide which copy of a replicated data item to access and to maintain the consistency of copies of replicated data items. - Distributed
Database Recovery –
The ability to recover from the individual site crashes and from new types of failures such as failure of communication links. - Security –
The basic function of DDBMS is to execute Distributed Transaction with proper management of the security of the data and the authorization/access privilege of users. - Distributed
Directory Management –
A directory basically contains information about data in the database. The directory may be global for the entire DDB, or local for each site. The placement and distribution of the directory may have design and policy issues. - Distributed
Transaction Management –
The basic function of DDBMS is its ability to devise execution strategies for queries and transaction that access data from more than one site and to synchronize the access to distributed data and basically to maintain the integrity of the complete database.
But these function increases the complexity of a DDBMS
over centralized DBMS.
Advantages of DDBMS
- The
database is easier to expand as it is already spread across multiple
systems and it is not too complicated to add a system.
- The
distributed database can have the data arranged according to different
levels of transparency i.e data with different transparency levels can be
stored at different locations.
- The
database can be stored according to the departmental information in an organization.
In that case, it is easier for a organizational hierarchical access.
- there were
a natural catastrophe such as fire or an earthquake all the data would not
be destroyed it is stored at different locations.
- It is
cheaper to create a network of systems containing a part of the database.
This database can also be easily increased or decreased.
- Even if
some of the data nodes go offline, the rest of the database can continue
its normal functions.
Disadvantages of DDBMS
- The
distributed database is quite complex and it is difficult to make sure
that a user gets a uniform view of the database because it is spread
across multiple locations.
- This
database is more expensive as it is complex and hence, difficult to
maintain.
- It is
difficult to provide security in a distributed database as the database
needs to be secured at all the locations it is stored. Moreover, the
infrastructure connecting all the nodes in a distributed database also
needs to be secured.
- It is
difficult to maintain data integrity in the distributed database because
of its nature. There can also be data redundancy in the database as it is
stored at multiple locations.
- The
distributed database is complicated and it is difficult to find people
with the necessary experience who can manage and maintain it.
No comments:
Post a Comment